 博客
HiGrid is one of the best jQuery grid plugin!
博客
HiGrid is one of the best jQuery grid plugin!
博客
HiGrid is one of the best jQuery grid plugin!
博客
HiGrid is one of the best jQuery grid plugin!
与 C 不一样,Go 中不支持关于指针的运算,比如 ptr ++ 等操作。
type Vertex struct {
X int
Y int
}
// create instance
v := Vertex{1, 2}
匿名结构体 struct
s := struct {
i int
b bool
}{1, false}
创建数组会给予默认值
var a [2]string // a[0] a[1] is both ""
a := [...]int {1, 2, 3} // ... 要求编译器根据 {} 中数据计算数组长度,如果没有 ... a就变成了 slice
数组是基本类型,值类型,函数/赋值都会发生整个数组的复制,在真实应用中很容易产生灾难,传递大数组我们可以使用数组指针
var a = [2]string{"John", "Susan"}
p := &a
fmt.Println(p[0], p[1])
Go 中设计哲学,让使用指针像使用引用一样简单
A slice does not store any data, it just describes a section of an underlying array.
Changing the elements of a slice modifies the corresponding elements of its underlying array.
Other slices that share the same underlying array will see those changes.
func slice1() {
names := [4]string{
"John",
"Paul",
"George",
"Ringo",
}
fmt.Printf("%T %v\n", names, names)
// 即使 names 是 [4]string array,但是 names 也能像 slice 一样使用
// 创建 slice 底层的 array 复用原来的 names array,极度容易产生 bug
a := names[0:2]
b := names[1:3]
fmt.Printf("%T %v\n", a, a)
fmt.Printf("%T %v\n", b, b)
b[0] = "Guang"
fmt.Printf("%T %v\n", names, names)
fmt.Printf("%T %v\n", a, a)
fmt.Printf("%T %v\n", b, b)
}
output:
[4]string [John Paul George Ringo]
[]string [John Paul]
[]string [Paul George]
[4]string [John Guang George Ringo]
[]string [John Guang]
[]string [Guang George]
slice 可以通过以下方式生成:
var s1 []string
var arr [2]string{"John", "Susan"}
s2 := arr[0:]
[3]bool{true, false, true} 创建一个长度为 3 的数组
[]bool{true, false, true} 底层会创建一个数组,然后创建一个 slice 引用底层的数组
slice 是引用类型,赋值/函数传递发生的是引用地址的复制,对于大数组的传递比较有帮助
对于 a := [10]int
以下操作等级:
a[:]
a[0:10]
a[:10]
a[0:]
length capacity
len(s)cap(s)slice 能在原有数组基础上扩张 extend,也就是直接把数组中后面的值内容读取进入 slice,length 因此变长
func test(){
s := []int {2, 3, 5, 7, 11, 13}
printSlice(s)
s = s[:0] // 清空 length,但是底层的数组和capacity不会改变
printSlice(s)
s = s[:4] // 在原有数组上扩张 extend,length = 4,capacity和底层数组没哟改变
printSlice(s)
s = s[2:] // 使数组可用长度较短两位,length-=2 capacity-=2,但是数组还是原来的数组
printSlice(s)
}
func printSlice(s []int) {
fmt.Printf("len=%d cap=%d %v\n", len(s), cap(s), s)
}
slice 操作就是修改 length capacity 数组起始指针,在没有涉及到插入元素过多,或者删除了大部分元素后,底层数组的扩张和收缩前,一切都不会涉及到底层数组操作
var s []int len(s)=0 cap(s)=0 还没有底层数组,此时 s == nil == true
slice 只能够和 nil 进行比较
使用 make 函数创建指定 length capacity 的 slice,其中创建的默认数组长度 == capacity
b := make([]int, 0, 5)
c := b[:2]
d := c[2: 5] // 这里即使 len(c) == 2,但是由于它指向的底层数组长度为5,所以这里 d 切片取得是底层数组 arr[2:5]
Slicing does not copy the slice’s data. It creates a new slice value that points to the original array.
Slice grow,在 cap(slice) < 1024 会成倍增加 slice capacity,但是 cap(slice) > 1024 每次增长 1.25 倍
t := make([]byte, len(s), (cap(s)+1)*2) // +1 in case cap(s) == 0
for i := range s {
t[i] = s[i]
}
s = t
将一个 slice 拼接到另一个 slice 后面
a := []int{1, 2, 3}
b := []int{4, 5, 6}
a = append(a, b...) // ... 以此取出元素,相当于 python *list **dict
range 用于遍历 array / slice / map
在 Go 中 _ 是一个特殊变量,不会被真正赋值,所以使用 _ 可以去掉 range 遍历中不感兴趣的变量
The zero value of Map is nil. A nil map has no keys, nor can keys be added. 需要先 make 创建 map
var m map[string]string
m = make(map[string]string)
m["Hello"] = "World"
or 在声明时初始化
m := map[string]string {
"Hello": "world",
"Family": "Father and mother I love you"
}
Insert or update: m[key] = value
Delete: delete(m, key) if key not in map, no error
Retieve: elem = m[key]
Test a key is in map or not: elem, ok = m[key] if key is in map, ok = true; else key = false and elem is the zero value.
WordCounter:
func WordCount(s string) map[string]int {
m := make(map[string]int)
t := strings.Fields(s)
for _, v := range t {
if counter, ok := m[v]; ok {
m[v] = counter + 1
} else {
m[v] = 1
}
}
return m
}
函数也是 value,函数可以当做值在函数或者变量之间传递
函数闭包:
package main
import "fmt"
func adder() func(int) int {
sum := 0
return func(x int) int {
sum += x
return sum
}
}
func main() {
pos, neg := adder(), adder()
for i := 0; i < 10; i++ {
fmt.Println(
pos(i),
neg(-2*i),
)
}
}
内层函数引用外层函数的变量,这样会促使外层变量被保存在内存中。闭包维基百科
method 不同于普通 fuction,method 有指定接受者的参数
// 定义结构体
type Vertex struct {
X, Y int
}
// 定义结构体的方法
func (v Vertex) Abs() float64 {
// 距离
return math.Sqrt(v.X * v.X + v.Y * v.Y)
}
func main() {
v := Vertex{3, 4}
fmt.Println(v.Abs())
}
Go 中可以给每一个每一个类型声明方法,而不仅仅是 struct 类型
类型别名:type MyFloat float64,此后就可以使用 MyFloat 来代替 float64
在方法传递中,struct 发生的是值复制传递
type Vertex struct {
X float64
Y float64
}
// 不会改变外围调用者的X Y值
func (v Vertex) A(f float64) {
v.X = v.X * f
v.Y = v.Y * f
}
// 传递指针,外围和内层使用的是同一个地址,修改会影响外围调用者
func (v *Vertex) B(f float64) {
v.X = v.X * f
v.Y = v.Y * f
}
func main() {
v := Vertex{3, 4}
fmt.Println(&v)
v.A(10)
fmt.Println(v)
v.B(10)
fmt.Println(v)
}
output:
&{3 4}
{3 4}
{30 40}
Go 中函数传递都是值传递,进行了拷贝复制。Go 中采用引用传递的一个地方是闭包中。
for i := 0; i < 3 i++ {
defer fmt.Println(i)
}
output:
2
1
0
for i := 0; i < 3; i++ {
defer func() {
fmt.Println(i)
}()
}
output:
3
3
3
所有的匿名函数都是引用了外部 i,所以输出结果都是相同的
为了防止上述情况,我们应该把 i 当做函数参数传递
for i := 0; i < 3; i++ {
defer func(i int){
fmt.Println(i)
}(i)
}
output:
2
1
0
函数使用指针传递参数的两个主要原因:
Go 中使得 interface 声明接口和具体 struct 实现方法分离,只要某个 struct 实现了所有 interface 接口的方法,那么该 struct 就是 interface 类型
如果接口 var i I 被赋予了 nil,那么方法中依然可进行方法调用,并不会触发空指针异常等,但是方法中传递的值是 nil
interface {}
var i interface{} 任何类型的值都可以赋予给 i,空接口常用在处理类型未知的情况下,例如fmt.Println() 可以接收任意数量任意类型的参数 func Print(a ...interface{})
interface type assertion
var i I
i = &T{"hello world"}
t := i.(*T)
如果 i 中不是 T 类型,就发生 panic
var i I
i = &T{"hello world"}
t := i.(F) // panic
var i I
i = &T{"hello world"}
t, ok := i.(F) // no panic
fmt.Println(t, ok)
如果 type assertion 成立,那么 ok == true,t 为对应的 T 值;否则 ok == false,t 为 类型 F 的 zero value。
Golang 中使用 Stringer 接口来打印格式化
type Stringer interface {
String() string
}
只要实现了 String() string 方法,那么使用 fmt.Sprintf("%v", v) 就会自动调用 String() string 方法,输出格式化字符串。
type error interface {
Error() string
}
自定义异常只需要实现方法 Error() string
Go 中定义一个 Reader 接口
type Reader interface{
func Read(b []byte) (n int, err error)
}
大多数标准库都实现了该接口,比如文件、网络、压缩、密码等等,我们可以通过该接口方便地访问数据
err = io.EOF在 package 中,有且只有以大写开头的变量、函数、类型会被外面所访问
Go 基本类型
bool
string
int int8 int16 int32 int64
uint uint8 uint16 uint32 uint64 uintptr
byte // alias for uint8
rune // alias for int32
// represents a Unicode code point
float32 float64
complex64 complex128
int uint uintptr 是 32 位如果当前系统为 32 位,64 位如果当前系统为 64 位
%T 类型%v 值在 Go 中没有默认类型转化机制,如果类型不匹配将会抛出错误
基本类型转化 T(v) T 是类型, v 是值,如:
i := 10
var f float = float(i)
// var f float = i # error
不同类型之间不能进行运算,甚至不能够进行比较 int + float error
常量与变量声明不一致
// 变量,使用 :=
var i := 1
// 常量,使用 =
const Pi = 3.14
常量还可以作为枚举
常量中比较特殊的关键字 iota
Numeric constants are high-precision values. Go 将保留所有精确值
package main
import "fmt"
const (
// Create a huge number by shifting a 1 bit left 100 places.
// In other words, the binary number that is 1 followed by 100 zeroes.
Big = 1 << 100
// Shift it right again 99 places, so we end up with 1<<1, or 2.
Small = Big >> 99
)
func needInt(x int) int { return x*10 + 1 }
func needFloat(x float64) float64 {
return x * 0.1
}
func main() {
fmt.Println(needInt(Small))
fmt.Println(needFloat(Small))
fmt.Println(needFloat(Big))
}
output:
21
0.2
1.2676506002282295e+29
new(T) 创建某个地址空间,返回对应的地址,然后将属性初始化为 zero value
make() 创建 slice / map / chan,并且完成对该类型的初始化,返回的是引用
如果这个世界上不是存在一个叫做ISIS的组织,那么我肯定以为该书所描述的只是虚构的故事,一切就像美国或者香港的犯罪电影,中央情报局、各国领袖、武器、间谍等等。
我是从比尔盖茨微信公众号中了解到有该书籍的存在的,能够引起我的兴趣的就是一个恐怖组织的头目–扎卡维是如何具有如此巨大的魅力能够让人们跟随他从事各种恐怖袭击,甚至是自杀式恐怖行为。
而我从书中得到的答案是:
本书主角是扎卡维,一个出生在约旦小村庄里面的小混混,早年辍学,暴利倾向,曾在监狱中待过好几年,最后因为约旦换领导人(父死子承),实行大赦免,不小心把扎卡维以及他的早年精神导师放出监狱。(PS:当局者最后发现名单上有扎卡维名字的时候并不希望赦免他,因为他实在太恐怖,但是因为赦免名单上已经有了国王的签名,一字千金)
扎卡维在监狱中的日子,在宗教上第一位导师麦格迪西(此人是监狱中的囚犯老大)的影响下,开始迷上了《古兰经》等伊斯兰教经典。但是麦格迪西所秉承的宗教信仰与扎卡维最后自身的极端宗教是两码事,后来师徒两人还会在互联网上发表意见批评对方的做法。
扎卡维热爱锻炼,在监狱中通过打磨石头为哑铃,体格非常强壮,他非常关心监狱中的伙伴。在监狱中还发生了一起重要的事件,囚犯们发动政变,推翻麦格迪西的地位,推荐扎卡维为新的领袖。监狱中的医生回忆道,扎卡维很少说话,但是他就像是能够通过眼神就控制一切的人,一看就是领袖。
ISIS的前身以及现在的领导人都是从监狱中培育出来的宗教极端分子,作者描述说,监狱中把重犯和轻犯统一关在一起,重犯们通过宣扬极端宗教思想,最后把轻犯也影响为极端宗教分子。其中ISIS的现领导人巴格达迪宣称,宗教思想最发达的是监狱,他在发展ISIS的过程中,还把监狱中的囚犯放出,将他们加入到ISIS组织中去。
扎卡维等人通过“圣战”来号召各地的勇士,他还想与“基地”组织合作,壮大自己的实力。“基地”组织是本-拉登控制的恐怖组织,遍布世界各地。可整个过程中,扎卡维并没有得到本拉登的赏识,直到美国征服开出通缉令,扎卡维的身价与本拉登的身价平齐。
本拉登身边养着不少宗教学者,他们的任务就是负责使用宗教知识,来解释本拉登旗下的“基地”组织的种种恐怖行为,通过宗教上的信仰,误导年轻的宗教分子走上极端,加入“基地”组织。但是本拉登本人受到全世界的通缉,除了拍摄视频外不能在任何地方露面,他只能够通过邮件等方式来下达命令。本拉登与扎卡维都是非常注重个人和所在组织的形象的,因为这会关乎他们会不会得到新人加入和来自国际上的融资。
通过宗教的力量,ISIS等恐怖组织得到世界上各地的人赞助,其中他们还会在Facebook、Twitter等网站上融资,有一些有钱人甚至飞到本地直接将钱送到他们手上,最为回报ISIS以该人的名字命名某组织。
扎卡维是通过伊拉克的宗教内战来赢得自己的地位,他挑拨离间多个宗教派,使他们内战,而扎卡维则是坐收渔人之利。他通过视频散布自己斩首美国人的视频来宣扬自己,公然挑战世界警察美国。当时美国的总统是布什,他每年在伊拉克上花费大量金钱去维护伊拉克的稳定。伊拉克沙漠下有大量的石油,而一旦这些石油全部由恐怖分子控制,石油可是工业的血液,黑色的金子,石油一旦失手,这就会造成世界大灾难,或者这也是为什么目前各国大力发展新能源的原因吧。还有一个原因就是战争会造成大量的移民,他们会涌向别人发达的、稳定的国家,比如西欧、北美。人口暴增,对于任何一个国家来说都是灾难,而后特朗普的移民新政就是为了驱逐非法移民。
扎卡维是在布什的任职期间斩获的,本拉登是在奥巴马期间斩获的。奥巴马与布什采用的军事策略不一样,他在选举时就声明不会干涉中东政治,因为布什每年花费大量纳税人的钱去做世界警察,纳税人非常不讨喜。而奥巴马说把这些钱都拿去做医改,每人都能够得到医疗保险,纳税人特别是社会底层的人们就欢喜了。(PS:医改已经被特朗普废除)
还有一个有趣的现象就是,政府没有这么多的金钱去和恐怖组织做斗争,极端分子在恐怖组织一年赚到的钱比在军队中多得多。
扎卡维只是通过号召人们前来参加“圣战”,利用了伊拉克当地人对美国军队的仇恨,因为伊拉克当地人都人为是美国人带来的战争,他们都非常痛恨美国人。扎卡维通过宗教信仰,给极端分子的仅仅只是一个承诺,他们死后就会进入天堂,而被他们炸死的美国人则下地狱。仅仅是这样一个宗教上的承诺,就吸引了无数人投奔他,自愿参加人弹行为。(人弹就是将炸弹绑在自己身上,自杀式的行为,在伊拉克是不允许搜索女人的身体的,女人会穿得很严密,所以女人就是一个人弹的好选择)
而人们后来发掘,扎卡维的真正目的不是报复美国人,因为扎卡维是约旦人,他前往伊拉克的原因就是这里动乱适合他的组织发展。所以他后来的恐怖行动中,有不少是针对伊拉克当地人,女人、孩子,这时候人们发现,扎卡维只是单纯地想要制造恐惧来控制人们,伊拉克渐渐地沦为了无政府装态,各势力都想要获得统治地位,不仅仅只有扎卡维。
而美国情报局是通过不断地捕获扎卡维的手下,通过拷问来得到情报,最终得知扎卡维还有另一位精神导师,他们每隔7~10天就会见面,美国军队通过跟踪该导师,找到了扎卡维的藏身之地,使用了空袭将扎卡维击毙。
一旦军方人员被捕,大部分都会背扎卡维亲自执刑,非常残暴。
极端宗教分子虽然在行事的时候非常勇敢、无情,有时甚至可以执行自杀式的任务,但是在被捕获后,有一些扎卡维的亲信都诚实地交待了情报。(PS:或者美国中央情报局的拷问有学问,能够诱导对人一步步突出真言)
而扎卡维死后,其组织的势力并没有消去,他的意志被传承下来,最后发展为现在的伊斯兰国。(PS:伊斯兰国和伊斯兰没有任何关系)
ISIS的真正崛起是在阿拉伯之春的爆发,其战地是在叙利亚。叙利亚人民希望当政者下台,国际上的国家领袖以及当时的奥巴马也发出声明需要叙利亚的当政者在xxxx-xx-xx日前下台,可是当政者不愿意下台(谁不贪婪权利地位呢?),从而引发了战争,这就提供了ISIS发展壮大的好机会,这情况就像扎卡维时期的伊拉克。
恐怖组织的主要金钱来源:
引发我的思考:
上述这么多的恐怖行为大部分都是借助了极端宗教的力量而达到的,无论是“圣战”的号召还是“上天堂,下地狱”的承诺。在《人类简史》和《未来简史》中都极大地强调了宗教的作用,宗教一开始的存在是为了解释某个当时人们还无法的解释的现象,或者帮助人们克服内心的恐惧。人类发展了这么旧,几乎每个民族都有各自的信仰,其中数基督教、伊斯兰教、佛教比较普遍,但是随着知识的发展,人类能够利用已有的知识去解释各种现象,而不是借助宗教去讲故事,我们年青一代似乎也没有如此宗教信仰,那么未来宗教会如何发展?未来的人会遗忘宗教吗?
待未来有空阅读《未来简史》或许能够得到答案,其作者是以色列著名的历史学家、宗教学家赫拉利。
在一个表中,一个列可能包含多个重复中值,通过 DISTINCT 仅仅列出不同的值
SELECT DISTINCT column_name, column_name FROM table_name;
= 等于
<> 不等于
`> 大于
< 小于
`>= 大于等于
<= 小于等于
BETWEEN 在某个范围内
LIKE 搜索某种模式
IN 指定针对某个列的多个可能值
用于规定要返回的记录的数目,尤其对于拥有大量记录的大型表非常有用。
# SQL Server
SELECT TOP number | percent column_name from table_name;
# MySQL
SELECT column_name from table_name LIMIT number;
# Oracle
SELECT column_name from table_name WHERE ROWNUM <= number;
LIKE 操作符用于在 WHERE 子句中搜索列中的特定模式
其中可以使用 % 通配符
SELECT * FROM table_name WHERE column_name LIKE '%key%"';
SELECT * FROM table_name WHERE column_name NOT LIKE 'xx';
通过使用 REGEXP 关键字可以使用正则表达式匹配
SELECT * from table_name WHERE column_name REGEXP 'regex_expression';
IN 操作符可以在 WHERE 子句判断是否在一个集合中
SELECT * FROM table_name WHERE column_name (NOT) IN (value1, value2, ..., valueN);
AND 关键字等价与逻辑 &&
| OR 关键字等价与逻辑 |
SELECT * FROM table_name WHERE expression1 AND | OR expression2;
BETWEEN 关键字可以过滤值在某个一个范围内
值的范围可以是数值、文本、日期
SELECT * FROM table_name WHERE column_name (NOT) BETWEEM value1 AND value2;
# 文本
SELECT * FROM table_name WHERE name BETWEEN 'A' AND 'H';
# 时间
SELECT * FROM table_name WHERE date BETWEEN '2017-02-26' AND now();
请注意,在不同的数据库中,BETWEEN 操作符会产生不同的结果! 在某些数据库中,BETWEEN 选取介于两个值之间但不包括两个测试值的字段。 在某些数据库中,BETWEEN 选取介于两个值之间且包括两个测试值的字段。 在某些数据库中,BETWEEN 选取介于两个值之间且包括第一个测试值但不包括最后一个测试值的字段。 因此,请检查您的数据库是如何处理 BETWEEN 操作符
时间格式可以使用文本插入,也可以使用 now() 等时间函数插入
INSERT INTO time_tabel (date) values ('2017-02-28');
INSERT INTO time_table (date) values (now());
在所有的 JOIN 子句中,如果没有加 GROUP BY ORDER BY 等排序命令,得到的结果均是以右表原本的记录的顺序,一一与左表进行匹配
使用左表去依次匹配右表的记录,只显示成功匹配的记录
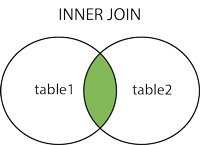
SELECT * FROM w.name, a.date FROM websites w JOIN access_log ON w.id=a.site_id ORDER a.count;
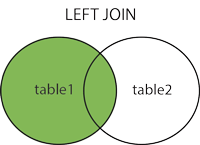
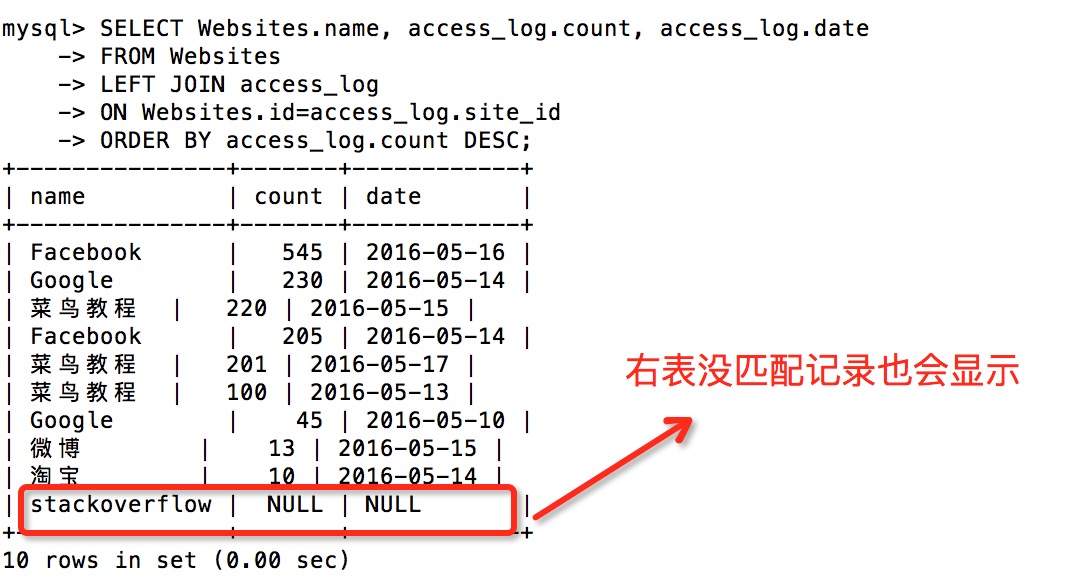
LEFT JOIN 关键字从左表(table1)返回所有的行,即使右表(table2)中没有匹配。如果右表中没有匹配,则结果为 NULL。
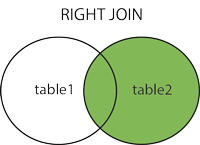
RIGHT JOIN 关键字从右表 table2 返回所有的行,即使左表中没有与之匹配。如果左表中没有与之匹配,则返回 NULL。
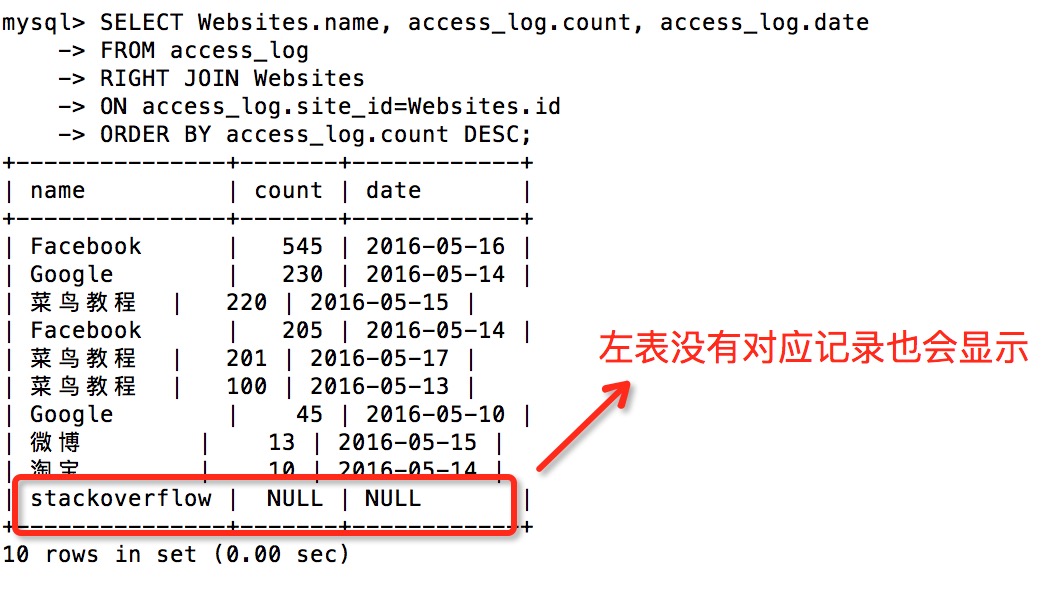
FULL OUTER JOIN 相当于是 LEFT JOIN + RIGHT JOIN。返回左表和右表的所有结果,如果左表中的数据在右表中没有与之对应的就返回 NULL,如果右表中的数据在左表没有与之对应的就返回 NULL。
MySQL 不支持 FULL OUTER JOIN。
UNION 操作符合并两个或者多个 SELECT 语句的结果。
注意:UNION 内部的每个 SELECT 语句必须拥有相同数量的列。咧业必须拥有相似的数据类型(经过尝试大多数都可以转化为字符串类型)。
SELECT column_name FROM table1
UNION
SELECT column_name FROM tables;
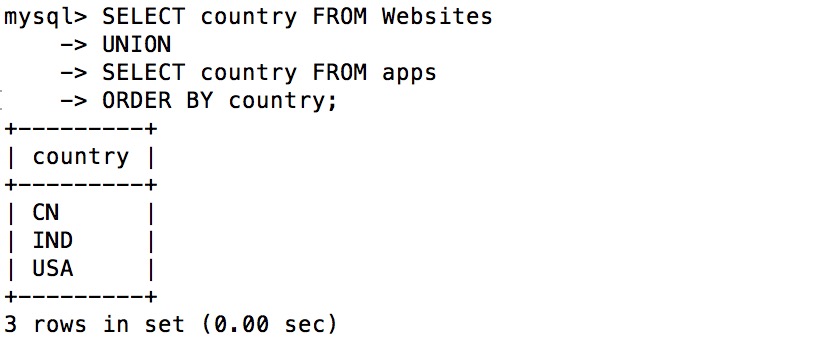
注释:默认的,UNION 操作符会选取不同的值。如果允许重复,请使用 UNION ALL
SELECT column_name FROM table1
UNION ALL
SELECT column_name FROM table2;
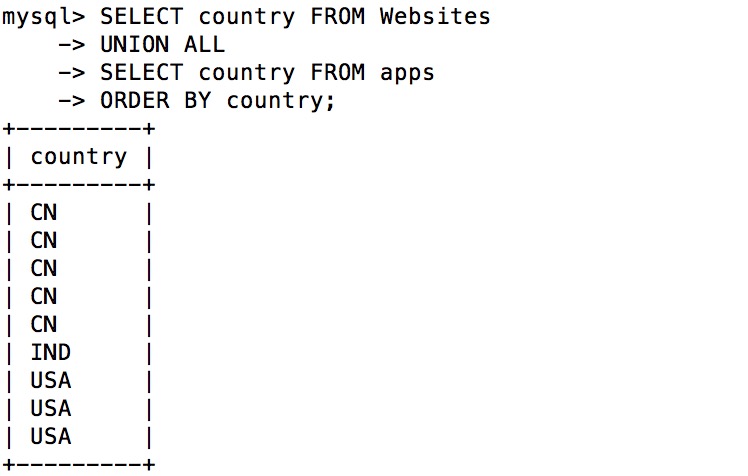
注释:UNION 结果集中的列名总是等于 UNION 中第一个 SELECT 语句的列名。
CREATE TABLE new_table SELECT column_name (AS new_column_name) FROM old_table WHERE expression;
通过 AS 语句来修改新表中字段名
复制数据只是单纯地复制数据以及数据类型到新表,但是各种外健主键约束等需要手动加。
把从一个表中的查询结果存储到新表中
可以使用 AS 子句来应用新名称
SELECT column_name (AS new_column_name)
INTO newtable
FROM table1;
MySQL 并不支持 SELECT … INTO 语句。
但是支持 INSERT INTO … SELECT
INSERT INTO table2
SELECT column_name FROM table1;
# 或者指定列
INSERT INTO table2 (column_name)
SELECT column_name FROM table1;
创建数据库
CREATE DATABASE dbname;
删除数据库
DROP DATABASE dbname;
CREATE TABLE Person(
P_id INT NOT NULL,
LastName VARCHAR(255) NOT NULL,
FirstName VARCHAR(255),
Address VARCHAR(255),
City VARCHAR(255),
# 在创建表时添加唯一约束
CONSTRAINT uc_PersonID UNIQUE(P_id, LastName)
);
# 或者直接修改表
ALTER TABLE Person ADD CONSTRAINT UNIQUE(P_id, LastName);
撤销 UNIQUE 约束
ALTER TABLE Person DROP INDEX uc_PersonID;
ALTER TABLE Person DROP CONSTRAINT uc_PersonID;
PRIMARY KEY = NOT NULL + UNIQUE
# 创建表时声明主键
CREATE TABLE Person(
P_id INT NOT NULL,
LastName VARCHAR(255) NOT NULL,
FirstName VARCHAR(255),
Address VARCHAR(255),
City VARCHAR(255),
# pk_PersonID 是主键,其有 P_id + LastName 组成
CONSTRAINT pk_PersonID PRIMARY KEY (P_id, LastName)
);
# 在表创建后加入主键
ALTER TABLE Person ADD CONSTRAINT pk_PersonID PRIMARY KEY(P_id, LastName);
撤销 PRIMARY KEY 约束
MySQL
# PRIMARY KEY 唯一,所以无需指定
ALTER TABLE Person DROP PRIMARY KEY;
SQL Server / Oracle
ALTER TABLE Person DROP CONSTRAINT pk_PersonID;
查看表信息
SHOW CREATE TABLE table_name;
FORENGN KEY 约束用于预防破坏表之间连接的行为。
FORENGN KEY 约束能防治非法数据插入外健列,因为它必须是指向的那个表中的值之一。
MySQL
CREATE TABLE orders(
id INT NOT NULL PRIMARY KEY,
orderNo INT NOT NULL,
p_id int,
# p_id 连接到 persons 表的 id
FOREIGN KEY (p_id) REFERENCES persons(id)
);
| **SQL Server | Oracle** |
CREATE TABLE Orders
(
id int NOT NULL PRIMARY KEY,
orderNo int NOT NULL,
p_id int FOREIGN KEY REFERENCES persons(p_id)
);
如需命名 FOREIGN KEY 约束,并定义多个列的 FOREIGN KEY 约束
CREATE TABLE orders(
id INT NOT NULL,
orderNo INT NOT NULL,
p_id INT,
PRIMARY KEY (id),
# 外健名称为 fk_perOrders
CONSTRAINT fk_perOrders FOREIGN KEY (p_id) REFERENCES persons(id)
);
添加 FOREIGN KEY 约束
MySQL
ALTER TABLE orders ADD FORENGN KEY (p_id) REFERENCES persons(id);
| **MySQL | SQL Server | Oracle** |
ALTER TABLE orders ADD CONSTRAINT foreign_key_name FOREIGN KEY (p_id)
REFERENCES persons(id);
撤销 FOREIGN KEY 约束
SHOW CREATE TABLE orders;可以查看对应的外健名
MySQL
ALTER TABLE orders DROP FOREIGN KEY foreign_key_name;
| **SQL Server | Oracle** |
ALTER TABLE orders DROP CONSTRAINT foreign_key_name;
“所有的存储引擎均对CHECK子句进行分析,但是忽略CHECK子句。” The CHECK clause is parsed but ignored by all storage engines.
CREATE TABLE persons(
id NOT NULL,
name VARCHAR(255) NOT NULL,
ADD CONSTRAINT chk_person CHECK (id > 0 AND name <> 'xxx' )
);
# 在创建表后添加 CHECK 约束
ALTER TABLE persons ADD CONSTRAINT chk_person CHECK(id > 0 AND name <> 'xxx');
DEFAULT 约束可以跟的是一个函数,如 now();
在创建表后添加 DEFAULT 约束
| **MySQL | SQL Server** |
ALTER TABLE persons
ALTER city SET DEFAULT 'New York';
Oracle
ALTER TABLE persons
MODIFY city DEFAULT 'New York';
撤销 DEFAULT 约束
ALTER TABLE persons
ALTER COLUMN city DROP DEFAULT;
CREATE INDEX 语句在表中创建索引,再不读取整个表的情况下,索引使书库库应用程序可以更快地查找到数据。
注释:更新一个包含索引的表需要比一个没有索引的表花费更多的时间,所以只在常常被所搜的列上创建索引。
在表中创建一个简单索引,允许使用重复的值。
CREATE INDEX index_name ON table_name (column_name);
在表中创建一个唯一的索引,两个行不能拥有相同的索引值。
CREATE UNIQUE INDEX index_name ON table_name (column_name);
如果需要索引不止一个列,可以如下:
CREATE INDEX index_name ON table_name (column_name_1, column_name_2);
撤销 INDEX
index_name 可以通过
SHOW CREATE TABLE table_name;查得
DROP INDEX index_name ON table_name;
# MySQL 上还可以这样:
ALTER TABLE table_name DROP INDEX index_name;
DELETE FROM table_name;
TURNCATE TABLE table_name;
ALTER TABLE table_name ADD column_name datatype;
2.删除列
ALTER TABLE table_name DROP COLUMN column_name;
3.修改列
ALTER TABLE table_name MODIFY column_name datatype;
MySQL
ALTER TABLE table_name AUTO_INCREMENT=start_number;
SQL Server
CREATE TABLE persons(
# start_number 起始值 interval_number 间隔
id INT IDENTITY(start_number, interval_number) PRIMARY KEY
);
Oracle
需要创建 SEQUENCE 对象
CREATE SEQUENCE seq
MINVALUE 1
START WITH 1
INCREMENT BY 1
# 缓存10个值提高性能
CACHE 10
插入SQL
INSERT INTO table_name(id, column1, column2) VALUES (seq.nextval, xxx, xxx);
视图是基于SQL语句的结果集的可视化表
创建视图
CREATE VIEW view_name AS
SELECT column_name(s) FROM table1;
调用视图
SELECT * FROM view_name;
修改视图
CREATE OR REPLACE VIEW view_name AS
SELECT column(s) FROM table1;
撤销视图
DROP VIEW view_name;
MySQL Date 函数
| 函数 | 功能 | 实例 |
|---|---|---|
| NOW() | 返回当前日期和时间 | 2017-02-26 16:23:16 |
| CURDATE() | 返回当前日期 | 2017-02-26 |
| CURTIME() | 返回当前时间 | 16:23:16 |
| DATE(date) | 提取日期或者日期/时间表达式的日期部分 | DATE(NOW()) ==> 16:23:16 |
| EXTRACT(unit FROM date) | 通过unit指定返回date中年/天/周/日/时/分/秒等 | EXTREACT(YEAR FROM now()) ==> 2017 |
| DATE_ADD(date, INTERVAL expr type) | 向日期添加指定的时间间隔 | DATE_ADD(NOW(), INTERVAL 1 DAY) ==> 2017-02-27 16:23:16 |
| DATE_SUB(date, INTERVAL expr type) | 向日期减去指定的时间间隔 | DATE_SUB(NOW(), INTERVAL 1 DAY) ==> 2017-02-26 16:23:16 |
| DATEDIFF(date1, date2) | 返回 date1 - date2 的天数 | DATEDIFF(‘2017-02-27’, ‘2017-02-28’) ==> -1 |
| DATE_FORMAT(date, format) | 以不同的格式输出日期(自定义) | DATE_FORMAT(‘2017-02-28 16:23:16’, ‘%b %d %Y %h:%i %p’) ==> FEB 26 2017 4:23 pm |
MySQL 日期格式
| 类型 | 格式 |
|---|---|
| DATE | YYYY-MM-DD |
| DATETIME | YYYY-MM-DD HH:MM:SS |
| TIMESTAMP | YYYY-MM-DD HH:MM:SS |
| YEAR | YYYY 或 YY |
2017-02-26 与 2017-02-26 00:00:00 并不会匹配
提示:如果希望查询简单且容易维护,请不要将日期中使用时间部分。
NULL 值与其他值不一样,NULL 无法使用运算符来测试 NULL 值,比如:= , < , <>
判断某个值是否是 NULL 使用 IS NULL
判断某个值是否不是 NULL 使用 IS NOT NULL
# IS NULL
SELECT * FROM persons WHERE city IS NULL;
# IS NOT NULL
SELECT * FROM persons WHERE city IS NOT NULL;
部分函数、数学或者逻辑运算与 NULL 运算后会得到 NULL 值。
如果我们希望把 NULL 在运算中用某个数据来代替 ,我们可以这样做:
SQL Server
SELECT ISNULL(NULL, 0); # return 0
Oracle
SELECT NVL(NULL, ' '); # return ' '
MySQL
SELECT IFNULL(NULL, 1); # return 1
# OR
SELECT COALESCE(NULL, 'ABC'); # return 'abc'
SQL 通用数据类型
| 数据类型 | 描述 |
|---|---|
| CHARACTER(n) | 字符/字符串。固定长度 n。 |
| VARCHAR(n) 或 CHARACTER VARYING(n) | 字符/字符串。可变长度。最大长度 n。 |
| BINARY(n) | 二进制串。固定长度 n。 |
| BOOLEAN | 存储 TRUE 或 FALSE 值 |
| VARBINARY(n) 或 BINARY VARYING(n) | 二进制串。可变长度。最大长度 n。 |
| INTEGER(p) | 整数值(没有小数点)。精度 p。 |
| SMALLINT | 整数值(没有小数点)。精度 5。 |
| INTEGER | 整数值(没有小数点)。精度 10。 |
| BIGINT | 整数值(没有小数点)。精度 19。 |
| DECIMAL(p,s) | 精确数值,精度 p,小数点后位数 s。例如:decimal(5,2) 是一个小数点前有 3 位数小数点后有 2 位数的数字。 |
| NUMERIC(p,s) | 精确数值,精度 p,小数点后位数 s。(与 DECIMAL 相同) |
| FLOAT(p) | 近似数值,尾数精度 p。一个采用以 10 为基数的指数计数法的浮点数。该类型的 size 参数由一个指定最小精度的单一数字组成。 |
| REAL | 近似数值,尾数精度 7。 |
| FLOAT | 近似数值,尾数精度 16。 |
| DOUBLE PRECISION | 近似数值,尾数精度 16。 |
| DATE | 存储年、月、日的值。 |
| TIME | 存储小时、分、秒的值。 |
| TIMESTAMP | 存储年、月、日、小时、分、秒的值。 |
| INTERVAL | 由一些整数字段组成,代表一段时间,取决于区间的类型。 |
| ARRAY | 元素的固定长度的有序集合 |
| MULTISET | 元素的可变长度的无序集合 |
| XML | 存储 XML 数据 |
**SQL 数据类型在不同平台的区别 **
| 数据类型 | Access | SQLServer | Oracle | MySQL | PostgreSQL | |
|---|---|---|---|---|---|---|
| boolean | Yes/No | Bit | Byte | N/A | Boolean | |
| integer | Number (integer) | Int | Number | Int Integer | Int Integer | |
| float | Number (single) | Float | Real | Number | Float | Numeric |
| currency | Currency | Money | N/A | N/A | Money | |
| string (fixed) | N/A | Char | Char | Char | Char | |
| string (variable) | Text (<256) Memo (65k+) | Varchar | Varchar Varchar2 | Varchar | Varchar | |
| binary object | OLE Object Memo | Binary (fixed up to 8K) Varbinary (<8K) Image (<2GB) | Long Raw | Blob Text | Binary Varbinary |
MySQL 主要有三种类型:Text(文本) 、 Number(数字) 、 Date/Time (日期/时间)
Text
| 数据类型 | 描述 |
|---|---|
| CHAR(size) | 保存固定长度的字符串(可包含字母、数字以及特殊字符)。在括号中指定字符串的长度。最多 255 个字符。 |
| VARCHAR(size) | 保存可变长度的字符串(可包含字母、数字以及特殊字符)。在括号中指定字符串的最大长度。最多 255 个字符。注释:如果值的长度大于 255,则被转换为 TEXT 类型。 |
| TINYTEXT | 存放最大长度为 255 个字符的字符串。 |
| TEXT | 存放最大长度为 65,535 个字符的字符串。 |
| BLOB | 用于 BLOBs(Binary Large OBjects)。存放最多 65,535 字节的数据。 |
| MEDIUMTEXT | 存放最大长度为 16,777,215 个字符的字符串。 |
| MEDIUMBLOB | 用于 BLOBs(Binary Large OBjects)。存放最多 16,777,215 字节的数据。 |
| LONGTEXT | 存放最大长度为 4,294,967,295 个字符的字符串。 |
| LONGBLOB | 用于 BLOBs (Binary Large OBjects)。存放最多 4,294,967,295 字节的数据。 |
| ENUM(x,y,z,etc.) | 允许您输入可能值的列表。可以在 ENUM 列表中列出最大 65535 个值。如果列表中不存在插入的值,则插入空值。注释:这些值是按照您输入的顺序排序的。可以按照此格式输入可能的值: ENUM(‘X’,’Y’,’Z’) |
| SET | 与 ENUM 类似,不同的是,SET 最多只能包含 64 个列表项且 SET 可存储一个以上的选择。 |
Number
| 数据类型 | 描述 |
|---|---|
| TINYINT(size) | -128 到 127 常规。0 到 255 无符号*。在括号中规定最大位数。 |
| SMALLINT(size) | -32768 到 32767 常规。0 到 65535 无符号*。在括号中规定最大位数。 |
| MEDIUMINT(size) | -8388608 到 8388607 普通。0 to 16777215 无符号*。在括号中规定最大位数。 |
| INT(size) | -2147483648 到 2147483647 常规。0 到 4294967295 无符号*。在括号中规定最大位数。 |
| BIGINT(size) | -9223372036854775808 到 9223372036854775807 常规。0 到 18446744073709551615 无符号*。在括号中规定最大位数。 |
| FLOAT(size,d) | 带有浮动小数点的小数字。在 size 参数中规定最大位数。在 d 参数中规定小数点右侧的最大位数。 |
| DOUBLE(size,d) | 带有浮动小数点的大数字。在 size 参数中规定最大位数。在 d 参数中规定小数点右侧的最大位数。 |
| DECIMAL(size,d) | 作为字符串存储的 DOUBLE 类型,允许固定的小数点。在 size 参数中规定最大位数。在 d 参数中规定小数点右侧的最大位数。 |
这些整数类型拥有额外的选项 UNSIGNED。通常,整数可以是负数或正数。如果添加 UNSIGNED 属性,那么范围将从 0 开始,而不是某个负数。
Date
| 数据类型 | 描述 |
|---|---|
| DATE() | 日期。格式:YYYY-MM-DD 注释:支持的范围是从 ‘1000-01-01’ 到 ‘9999-12-31’ |
| DATETIME() | *日期和时间的组合。格式:YYYY-MM-DD HH:MM:SS 注释:支持的范围是从 ‘1000-01-01 00:00:00’ 到 ‘9999-12-31 23:59:59’ |
| TIMESTAMP() | *时间戳。TIMESTAMP 值使用 Unix 纪元(‘1970-01-01 00:00:00’ UTC) 至今的秒数来存储。格式:YYYY-MM-DD HH:MM:SS 注释:支持的范围是从 ‘1970-01-01 00:00:01’ UTC 到 ‘2038-01-09 03:14:07’ UTC |
| TIME() | 时间。格式:HH:MM:SS 注释:支持的范围是从 ‘-838:59:59’ 到 ‘838:59:59’ |
| YEAR() | 2 位或 4 位格式的年。注释:4 位格式所允许的值:1901 到 2155。2 位格式所允许的值:70 到 69,表示从 1970 到 2069。 |
即便 DATETIME 和 TIMESTAMP 返回相同的格式,它们的工作方式很不同。在 INSERT 或 UPDATE 查询中,TIMESTAMP 自动把自身设置为当前的日期和时间。TIMESTAMP 也接受不同的格式,比如 YYYYMMDDHHMMSS、YYMMDDHHMMSS、YYYYMMDD 或 YYMMDD。
SELECT site_id, count FROM access_log WHERE count > (SELECT AVG(count) FROM access_log);
COUNT() - 返回行数
FIRST() - 返回第一条记录 注释:只有 MS Access 支持 FIRST()
LAST() - 返回最后一条记录 注释:只有 MS Access 支持 LAST()
MAX() - 返回最大值
SELECT MAX(column_name) FROM table_name;
SELECT MIN(column_name) FROM table_name;
SELECT SUM(column_name) FROM table_name;
SELECT UCASE(column_name) FROM table_name;
SELECT LCASE(column_name) FROM table_name;
SELECT MID('WORK HARD', 1, 4); # return WORK
注释:在 MySQL 中是前闭后闭, 字符串是从第 1 位开始算
注释:在MySQL 中是 LENGTH(),一个汉字长度为3,一个英文长度为1
SELECT ROUND(column_name,decimals) FROM table_name;
注释: ROUND 返回值被转化为一个 BIGINT!
NOW() - 返回当前的系统日期和时间
FORMAT() - 格式化某个字段的显示方式
SELECT COUNT(column_name) FROM table1;
返回指定列的数目,NULL 不计数
SELECT COUNT(DISTINCT column_name) FROM table1;
返回指定列不同值的数目
SQL Server
SELECT TOP 1 column_name FROM table1 ORDER BY column_name ASC;
MySQL
SELECT column_name FROM table1 ORDER BY column_name ASC
LIMIT 1; # LIMIT number 指定最多只返回多少条记录
Oracle
SELECT column_name FROM table1 ORDER BY column_name ASC
WHERE ROWNUM <= 1;
SQL Server
SELECT TOP 1 column_name FROM table
ORDER BY column_name DESC;
MySQL
SELECT column_name FROM table1 ORDER BY column_name DESC
LIMIT 1;
Oracle
SELECT column_name FROM table1 ORDER BY column_name DESC
WHERE ROWNUM <= 1;
GROUP BY 语句用于结合聚合函数,根据一个或多个列对结果集进行分组。
SELECT column_name, aggregate_function(column_name)
FROM table_name
WHERE column_name operator value
# 相同的 column_name 的行将会被归为一行
GROUP BY column_name;

SQL 中增加 HAVING 子句的原因是:WHERE 关键字无法与聚合函数一起使用,HAVING 子句就是用来与聚合函数一起使用的。

